I recently published an article analysing Spotify’s move into the datafication of health, exercise and wellness of users (I have written other posts on this paper here, here and here). Their headline rationale for this is to provide better personalisation and automation of recommendations of content for users. However, I suggested there was an underlying driver to support more effective targeted marketing. This, I suggested, was driven by Spotify’s inability to maintain profitability from their subscription service, despite being easily the world’s largest music streaming platform. I also proposed that they were not even seriously searching for profitability, instead, relying on “patient capital” investors to whom they could construct a story of future profitability, or at least never-ending growth.
Since writing this article their strategy has changed a little as the investment community has moved more from a focus on growth to profitability with capital becoming less “patient” in their wait for returns.
However, it seems that the shift to advertising is only likely to increase with other streaming services taking a similar approach. Disney+, Amazon’s Prime Video and Netflix are all introducing free or cheaper ad-funded tiers to their services in their search for growth and/or profitability.
This is not simply a change to the funding model but will impact on content and user experience and, as my paper showed will lead to different forms of datafication of users with potential impacts on how users are perceived by the platforms. Developments since I published this article hint towards other changes to Spotify’s approach but still relate to some of the insights I suggested.
Many users will have been delighted by Spotify recently granting access to thousands of audiobooks on the platform with, as yet, no increase in subscription costs. This is, no doubt, partly a strategy aimed at retaining users and increasing their engagement with the platform which could enable smoother introduction of price rises in the future.
But they have concurrently been increasing their investment in AI and particularly large language models through a partnership with Google Cloud to use their Vertex AI Search system. This will allow Spotify to analyse the content, not just the metadata, of audiobooks and podcasts opening up a huge new vista of data points on the words spoken and emotions expressed in the texts themselves.
This will enable the platform to build better recommendation systems for audiobooks and podcasts but will also help them to generate better “taste profiles” of users for targeted advertising. While these kinds of profiles have been very effective in generating effective targeted marketing for other platforms, such as Facebook, but due to the more “passive” way people tend to use Spotify they face a significant problem. As I highlight in my article:
Spotify faces a significant ‘cold-start’ problem as engagement with ads on music streaming platforms is low. To tackle this, user activity is combined with demographic data and music taste to infer ad preferences for a subset of ‘seed users’ who have interacted with ads (Pustejovsky et al., 2022). Other users are then placed in a theoretical multi-dimensional space, using a ‘nearest-neighbour search’, to find the ‘seed users’ to whom they are closest and have their ad preferences applied (Pustejovsky et al., 2022). Users are, then, clustered together in a ‘vector space’ according to various data points based on their musical preferences and other contextual data such as time of day, emotional state, running activity, heart rate, etc. (Pustejovsky et al., 2022).
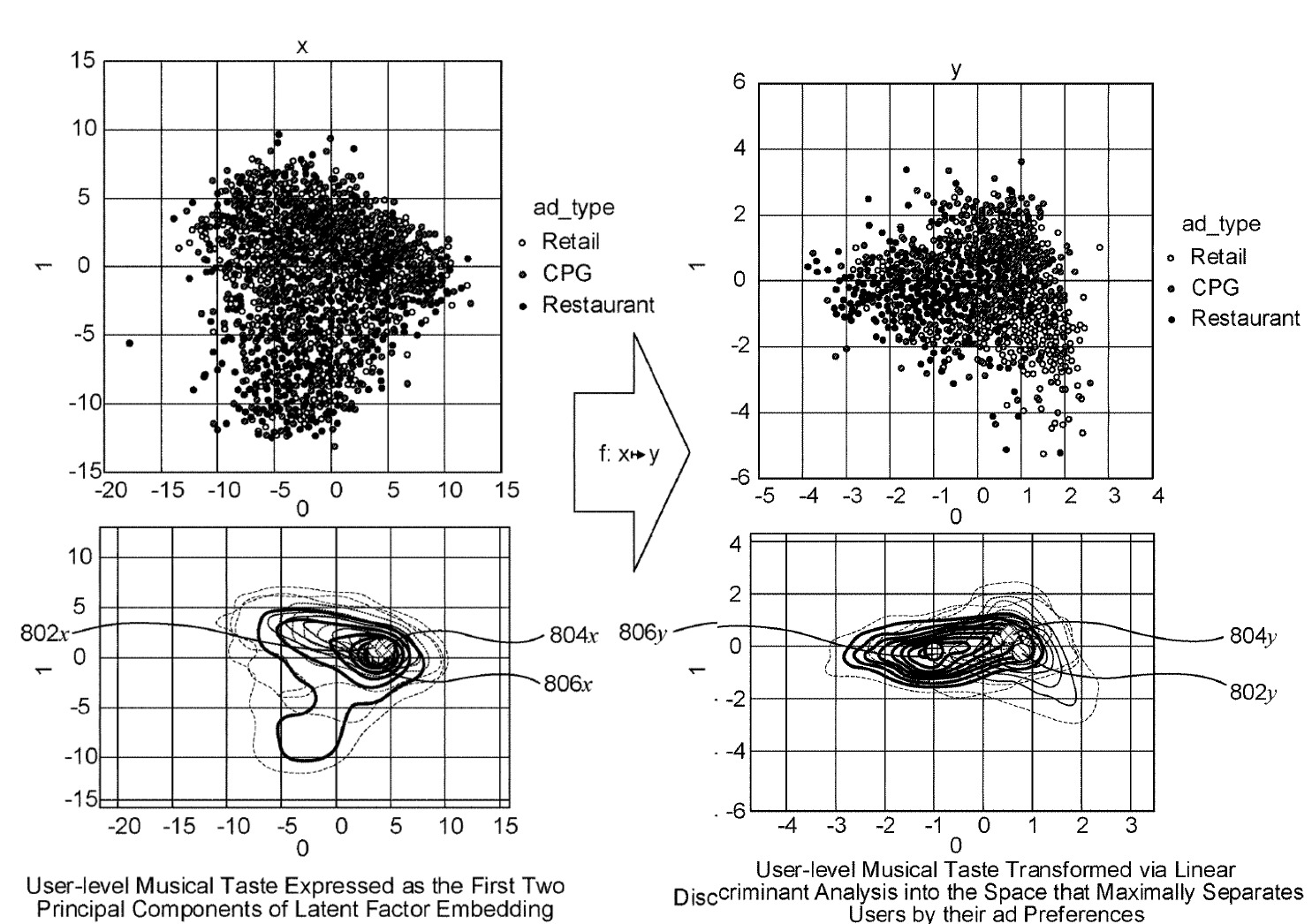
Due to their greater emphasis on advertising Spotify need to find more effective ways of aligning user engagement with their platform (eg what they listen to) with consumer behaviour. So, creating new data points on users and content and using these to generate taste profiles which are then associated with consumer will become increasingly important. A central part of this will also be situating users in clusters with other users (see image above) so predictions about one user can be mapped on to another. In the process a whole array of profiles and social relationships between us and others are being constructed without our knowledge.
