
****UPDATE****
I have updated this post as since I initially published it I have generated new analysis from more data using this software. The updated section is at the end of the post.
*************
It has become an almost daily occurrence to read a story about an online company being hacked or carelessly leaking its files meaning that their vast quantities of data become compromised. There also seems to be a growing assumption that purveyors of online services have a “creepy” level of interest in our personal data.
Although Facebook, Twitter and other social networks promote sharing amongst users they are not too keen on revealing precisely what it is they know about us. Actually, that is not quite true. Facebook do allow users to download their own raw data but this is not where the real interest lies. These data become powerful and interesting when we understand how they are used to categorise us and predict our behaviour. What do our data say about us?
There is a way to get a sense of this through using Data Selfie which is an extension for the Chrome browser which tracks your Facebook usage. The data are presented back to you through the kinds of analysis which are used by Facebook. As the developers say:
Data Selfie is an application that aims to provide a personal perspective on data mining, predictive analytics and our online data identity – including inferred information from our consumption.
As we will see Facebook don’t just collate information on who are your friends and the identifying details you upload (eg. what school, college and university you went to and the city where you live). Rather, they monitor which profiles you look at the most, what external media you read or watch and how long you spend doing this. These are the kinds of data which were used by the “Vote Leave” campaign in the EU referendum and the Trump presidential campaign team to target specific groups of potential voters and has been suggested had a decisive influence on the results.
Data Selfie want to encourage us to think about the difference between how we present ourselves and who Facebook thinks we are:
How do our data profiles, the ones we actively create, compare to the profiles made by the machines at Facebook, Google and Co. – the profiles we never get to see, but unconsciously create?
Who is in control of how we are perceived? Are we constructing our identities or is Facebook doing it for us?
It is perhaps the secretive nature of this analysis which is particularly unsettling. It seems that when “normal” users look at our profiles they (mostly) see what we have chosen to share about ourselves; the photos we upload and the statuses we have composed. Whether my friends see my updates or someone else’s on their timeline is determined by Facebook’s algorithms but the content is pretty much what I chose.
But the data which Facebook sees, and which they sell to advertisers or share with governments, is of a completely different order. This is what Data Selfie helps us to see. By allowing us to see our Facebook data in this way it is like seeing through the eyes those who watch us.
Analysing my data
Below I will talk through some of my data and how the analysis makes some quite surprising assumptions about me. But you must keep in mind that I have only had Data Selfie running for a couple of weeks (while Facebook has been tracking me for about 10 years) and it only collates data while I’m using Chrome (whereas Facebook tracks me while using my phone and iPad as well). So the data I can see is relatively limited which perhaps explains why some of their assumptions about me are a bit off (unless they are right and it is my self-perception which is skewed!).
This first image shows a general overview of my activity for the last few days which shows that I mostly “looked” (green crosses) rather than clicking on links or typing anything. I feel that I do read quite a lot of articles from links posted on Facebook but perhaps I do this more on other devices. It also seems to show that I tend to look early morning (around the time I start work) and mid-afternoon (perhaps when my attention is waning).

This box shows “important” keywords in articles (or perhaps videos) which I have accessed and the sentiment related to them.

I assume this has been ascertained through sentiment analysis of words used in the content. So if someone were analysing my data they might assume I’m attracted to content which is negative about “classic social media” (whatever that is) and the proposed two year university degrees in the UK (true).
At the same time an observer might assume I like to read articles which are positive about La La land, Donald Trump and Central London BUIRA (which I’d never heard of).
The “entities” box is an attempt to ascertain my sentiment towards particular people, places or concepts (rather than keywords as with the box above) based on content I have viewed. A Chris Till analyst might might assume I am positive about Theresa May, the Oscars, UK, Brexit and Donald Trump (yikes!). While simultaneously being negative about US and Britain.

This box shows the data which are used to try to guess my personality.

This analysis is based on the pages I have looked at and what I have typed but as the first graph showed that I don’t write many posts this must be mostly about what I have read. So, these data suggest I am pretty average but tend towards being “conservative and traditional”, “impulsive and spontaneous”, “contemplative”, “competitive” as well as “laid back and relaxed”. I think it is quite hard to assess yourself in relation to these qualities but I would probably mostly disagree with the ones which give the strongest reading. However, the data it is using is quite limited.
This box is an attempt to guess my religion (based on the pages in my feed).
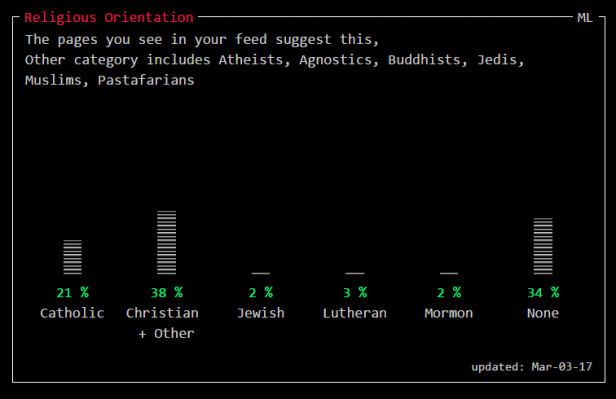
The analysis suggests I am either a Christian or an atheist. I would identify as atheist so they are not doing too badly here. This box in particular shows up one of the key differences between this kind of data and traditional census type data. Allowing people to self-identity throws up odd categories like Jedi (which some have worked to include in the official UK census) and Pastafarian.
The “Political Orientation” data suggests I am “liberal” (in American terms) which is probably roughly correct. However, the high “conservative” score aligns with the previous assumptions made about my positive attitude towards Trump, May and Brexit.
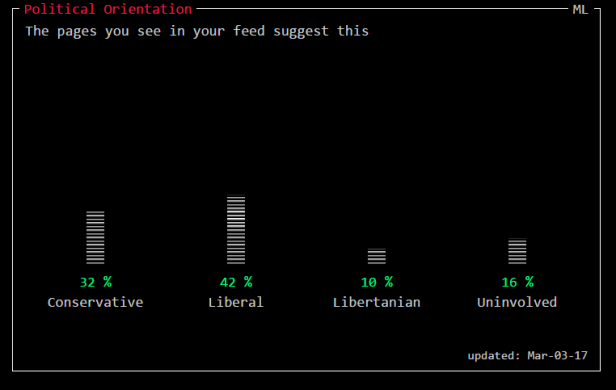
The “Other Predictions” data makes a guess that I am in the 49th percentile for intelligence meaning 51% of people are more intelligent than me (no comment!) and slightly more people are more satisfied with their life than I am (to me this suggests there are some pretty ecstatic people around). They also guess that I am psychologically female which I assume is based on some kind of gender identity scale. For a really good analysis of the dubious history of such scales see Jill Morawski’s article (sorry paywalled).
So, what does all of this tell me? It looks like perhaps Facebook doesn’t know me all that well as I wouldn’t identify with a lot of the characteristics they have assumed about me. But perhaps this is because I am breaking out of my “echo chamber” by reading articles which I don’t agree with. However, I don’t feel like I do that as much as this would suggest. Of course probably the biggest issue with the data is that it is quite limited. Also, two of the most important categories, at least for Facebook, (“shopping preferences” “Health+Activity+ other preferences”) don’t yet have sufficient data.
What is most interesting is not so much what they do know about us but rather what they want to know about us and how they go about categorising us. As the philosopher of science Ian Hacking has pointed out, the categorisation of people is not a neutral act. When we create “human kinds” (categories or types of people) this has a “looping effect”. He suggests that:
To create new ways of classifying people is also to change how we can think of ourselves, to change our sense of self-worth, even how we remember our own past. This in turn generates a looping effect because people of the kind behave differently and so are different.
The problem with the kind of categorisation which Data Selfie reveals is that we are not aware of the classifications which are produced by social networks but our experiences are shaped by them anyway. The adverts and news articles we see online are chosen for us by the kinds of analysis I’ve discussed here. More worryingly social media data (and the classifications they produce) are used to identify potential terrorists and in China to feed into an all purpose “social credit system” which will determine peoples’ access to services and act as a tool of “social management”. Tools such as Data Selfie are really valuable for highlighting how opaque systems are being used to analyse us but we also have to think very carefully about how these might be used.
********UPDATE********
When I initially published this post Data Selfie had not generated sufficient data to produce analysis for 2 of the major areas. So, now that new data has been analysed I present here the last two boxes. Firstly, “Shopping Preferences”.
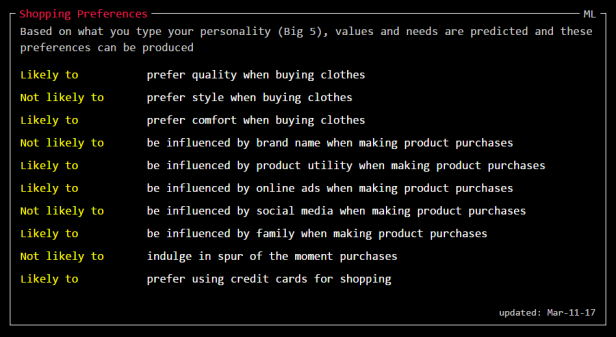
The analysis suggests that I am “not likely to prefer style when buying clothes”. I would suggest this is wrong but then other people may think differently. I’m also thought to be “likely to prefer comfort when buying clothes” which I am pretty sure is not true. The analysis also assumes I am “likely to be influenced by product utility when making product purchases” and “not likely to indulge in spare of the moment purchases”.
Overall, I think they have got me fairly right in terms of product purchases generally. If I was to buy a new laptop I would do this rationally and would look at a lot of different factors and try to make an informed decision. However, I think they’be probably got me wrong in terms of buying clothes as they seem to have me down as “practical” and (I think) “casual”.
The final box is “Health + Activity + Other Preferences”. Here they suggest that I am “not likely to eat out frequently” and “not likely to have a gym membership”. On both of these they are very wrong. On the remaining three they are broadly right.
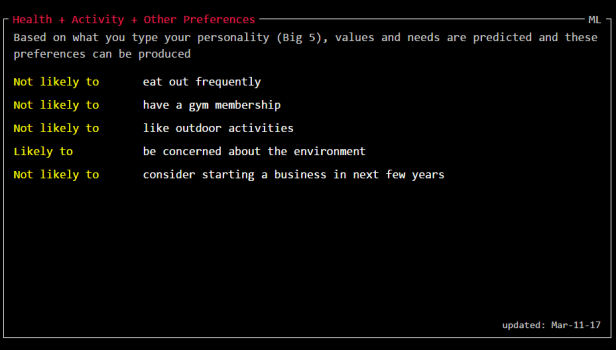
These two sections of analysis are based on my personality type according to the “Big 5 Personality Traits” as defined in the “Personality Prediction” box above. This is probably the most widely used model of personality in psychology and has been particularly influential in marketing. In this case my scores on the personality scales are probably determined by the amount of friends I have, how many likes I generate, how many groups I’m associated with and similar quantified measures as in this study. I assume this as the study linked to was written by researchers from the “Psychometrics Study Centre” at The University of Cambridge and others from Microsoft who developed a tool called “Magic Sauce” which I believe is the basis of Data Selfie.

interesting piece. i don’t know if i personally care about this happening to me. i know i’m not a robot, but it is concerning something like this is used to determine a persons liability or whether they are a terrorist threat, which is simply ridiculous. i am, i like to think, in control of my choices, but i think that may stem from being aware of the interference of advertising & not paying mind to it. but i can see the danger & concern for those with more malleable minds.
I suppose it is more or less worrying depending on your particular social position. Those who are in a precarious position (eg RE immigration status) might be worried. Also, the use of these categories to target political advertising (which others don’t see) is perhaps worrying.
do you see it as an inevitable by product of social media, i mean people do want it & someone is always going to exploit something, so do you see any way around it? i may not agree with it, but it appears to me a sort of trade off for the use of the service, a tariff of sorts. i don’t give a crap if Facebook exists or not, but people do in general, though they may say otherwise; yet they want it free & without imposing, but is that possible?
I don’t think it is inevitable. It is due to the funding model which has been collectively chosen for the internet. It might be different if we paid or a fee for the use of sites then they would not need to sell our data to advertisers and might compete over who can best insulate us from such surveillance. Alternatively, the internet could have been developed as a “public good” and paid for (at least partly) through taxation like (in the past) telecoms, railways, education, etc. This is an interesting article on how the ad-funded model took over the internet: https://www.theatlantic.com/technology/archive/2014/08/advertising-is-the-internets-original-sin/376041/
thanks Chris. i see your point.